

SustAIned Future: Through the looking glass
By Xavier Evans & Louisa Mesnard.


Welcome to the Elaia Sustainable AI newsletter. Every two weeks, Elaia’s Sustainability team will dive into open questions at the nexus of two of the biggest trends of our generation: the rapid development and application of AI and our responsibility to improve societal and planetary health.
A common critique of AI’s rapid development has focused on the environmental impact of training and prompting models in ever larger GPU clusters. While a valid concern, there is a lack of data and transparency regarding the impact of any given model or prompt.
This matters because AI energy use is scaling with adoption. The impact comes not only from training frontier models, but from running them millions or billions of times in daily use. Chatgpt alone answers billions of prompts every single day. And we simply don’t know the impact of all that activity.
Opacity enables the proliferation of myth
In the place of verifiable data, myths catch hold. Sasha Luccioni, Boris Gamazaychikov, Theo Alves da Costa, and Emma Strubell recently collaborated on an excellent mythbusting article looking at common myths about AI (both positive and negative), tracking down their origins and dispelling untruths.
One of our favourite myths they address is the often-quoted stat that “a request to ChatGPT consumes ten times more energy than a Google search”. The comparison has been repeated in tech media, mainstream news, and even a 2024 Goldman Sachs report.
As the article demonstrates, the statement came from a Google executive in 2023, was not based on OpenAI or Microsoft data, and relied on electricity figures for Google search from 2009. Despite its shaky quantitative underpinning, the comparison stuck thanks to a lack of a viable alternative comparison or means to quantify the environmental impact of AI.
Myth-making can go both ways in this debate. A bullish assertion about decarbonisation through the deployment of AI is a favourite of corporates who develop and deploy AI systems globally. First published by BCG in 2021 and again in 2023 (in a report commissioned by Google for COP26), the stat has taken on a life of its own in the “AI for sustainability” argument. Fortunately in the fast-moving AI zeitgeist, this claim has fallen out of fashion, but demonstrates a constant bias towards simple heuristics when grappling with the complexity of sustainability in the development of AI.

Data-driven transparency
The greater point here is the impact of opacity: we struggle to identify the energy, water, and carbon emissions impact of either individual prompts or the lifecycle of models.
Admittedly, measuring the footprint of AI is not as simple as putting a wattmeter on a server. Training workloads shift dynamically across GPU clusters, inference traffic varies second-to-second, and water use depends on local climate and cooling design. Different cloud regions draw from different electricity grids, each with different energy mixes and their own carbon intensities.
That is not to say it is impossible. Some AI model companies have started to publish analyses of the impact of their operations: Mistral released a lifecycle assessment (LCA) of their model from model conception through to end-user equipment. The analysis broadly matched an LCA conducted by independent researchers from the Sustainable AI Lab at the University of Bonn, led by Sofia Falk.
Google released a slightly less detailed analysis of their energy, emissions and water impact of inference (the process of generating outputs in response to prompts) on Gemini, but did not include training or hardware impacts (which are generally accepted to be two of the most impactful parts of the AI lifecycle). The analysis is useful, but it highlights a gap in the industry: inference data is easier to report today because it runs in production with telemetry, while training workloads often span distributed clusters that lack unified reporting. Inference likely also represents the greater energy demand across compute compared to training, simply because it happens continuously at scale. However, the tipping point depends heavily on model size, usage patterns, and hosting infrastructure, meaning generalised claims should be made with caution.
Other analyses have complemented this approach by analysing the marginal differences between prompts or open source models in the inference stage. The Hugging Face team is leading the way here, developing the AI Energy Score leaderboard and publishing breakdowns of quality and energy consumption of open-source video generation models. The latter used Code Carbon to track CO2 output for any given prompt.
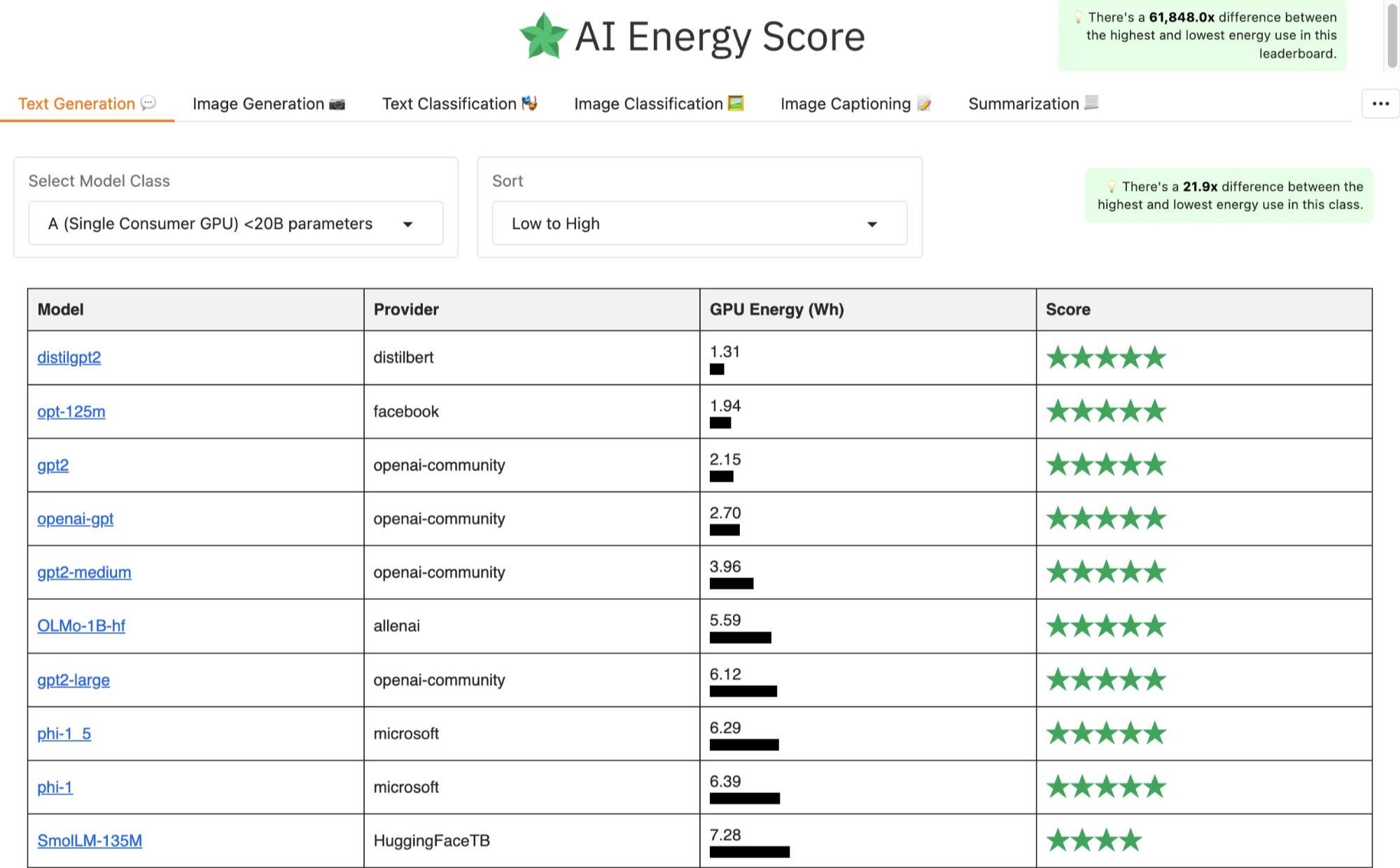
Leverage points
Understanding the impact of AI will continue to need more data, more analysis, and more transparency. As we discussed in our feature with Reframe Venture, the industry is singularly focused on speed of deployment above all else.
However, more data and transparency could drive further innovation to address areas of greatest leverage and reduce associated costs, while also potentially being a point of competitive advantage amongst sustainability-conscious consumers.
There are two meaningful leverage points:
(1) Model-level efficiency reducing the energy required per token or per task, implemented through smaller models, quantisation, or distillation.
(2) Infrastructure-level efficiency reducing the embodied and operational footprint of the hardware and data centres that run the models.
The energy-per-token approach taken by Hugging Face and others focuses on the former, whereas some of the broader LCA analysis is important for the latter. Both matter, but they are measured differently, optimised differently, and governed differently.
With plenty of opportunity for innovation in this space, we will continue to dive into the opportunities presented by both sides. Upcoming editions will focus on the opportunity presented by a potential post-LLM paradigm, as well as the options to improve the sustainability of physical supply chains and infrastructure that houses and runs AI systems.