

A post-LLM paradigm
By Xavier Evans & Louisa Mesnard.


Welcome to the Elaia Sustainable AI newsletter. Every two weeks, Elaia’s Sustainability team will dive into open questions at the nexus of two of the biggest trends of our generation: the rapid development and application of AI and our responsibility to improve societal and planetary health.
In a previous edition, we examined the lack of transparency regarding environmental data in the global race to develop AI systems. We concluded that there were two meaningful leverage points:
Model-level efficiency reducing the energy required per token or per task, implemented through smaller models, quantisation, or distillation.
Infrastructure-level efficiency reducing the embodied and operational footprint of the hardware and data centres that run the models.
This edition examines the former, and how greater specialisation and sophisticated triaging of tasks could reduce the overall energy and sustainability burden of AI systems
The pursuit of increasingly advanced AI systems is a tale of chasing both depth and breadth of capability. Frontier model developers want to do it all, and do it well, leading to an explosion of parameters. GPT-3’s 175 billion parameters seemed massive in 2020; by 2024, models were reportedly approaching or exceeding a trillion parameters. Model developers chased size at all costs to prove capability, absorbing increased costs as a necessary function of competing against each other to build the most advanced AI systems.
Those costs are starting to catch up. Rumours suggest that just the cost of inference exceeds total revenue for OpenAI, making an economic model built on massive data centre CAPEX and training costs, on top of inference costs, a non-starter. GPT5 alone is expected to have cost at least $1bn to train.
A big component of this cost burden is energy demand. While it is hard to pin down an accurate average for the required energy for each task sent to an LLM, there is a direct relationship between compute and energy demand, and therefore cost.
The shift towards AI agents amplifies these concerns given that agents are autonomous AI systems. For example, an AI project manager could take a broad objective, break it into tasks, gather relevant data, coordinate with tools and services, generate intermediate outputs, and revise the plan as circumstances change, all without requiring step-by-step instructions.
Some agents such as Replit and Anthropic’s Claude agents can continuously operate. If built on top of ever-larger frontier LLMs, the inference cost can balloon, as well as facing significant issues of runaway hallucination and a degradation of security.
Striving for better performance in models under the conventional “bigger is better” paradigm is no longer viable. Instead, AI model developers and deployers are becoming more sophisticated in the implementation layer.
Shrinkflation
Models can be adjusted ex-post by reducing the amount of compute called for any given prompt, particularly when the use case of a given language model is known to be limited. The philosophy here is simple, less compute is always less energy intensive, and thus a smaller model will always be less energy hungry than a larger model at the exact same task.
One approach is pruning. Open source models can be pruned after release to fit a more limited use case. Pruning turns off parts of the model unnecessary for the expected use case upon deployment. The end result is a smaller model, requiring less compute to execute a task. Companies such as Pruna AI are offering this as a service, democratising access to more efficient off-the-shelf models.
Another option is quantisation, where the digital signals within a model are transformed into less precise formats to save unnecessary compute. Quantisation has been deployed by organisations such as GreenPT, which claims to take models that ordinarily run on two H100 chips and squeeze them onto one. GreenPT’s CEO advocates for an additional layer of prompt optimisation, which reframes human-inputted prompts for closer alignment with a compute-optimised prompt architecture.
In practice, this approach is already used in image-generation systems, where quantising models like Stable Diffusion allow developers to halve the required GPU memory and deploy them on cheaper hardware without major degradation in image quality.
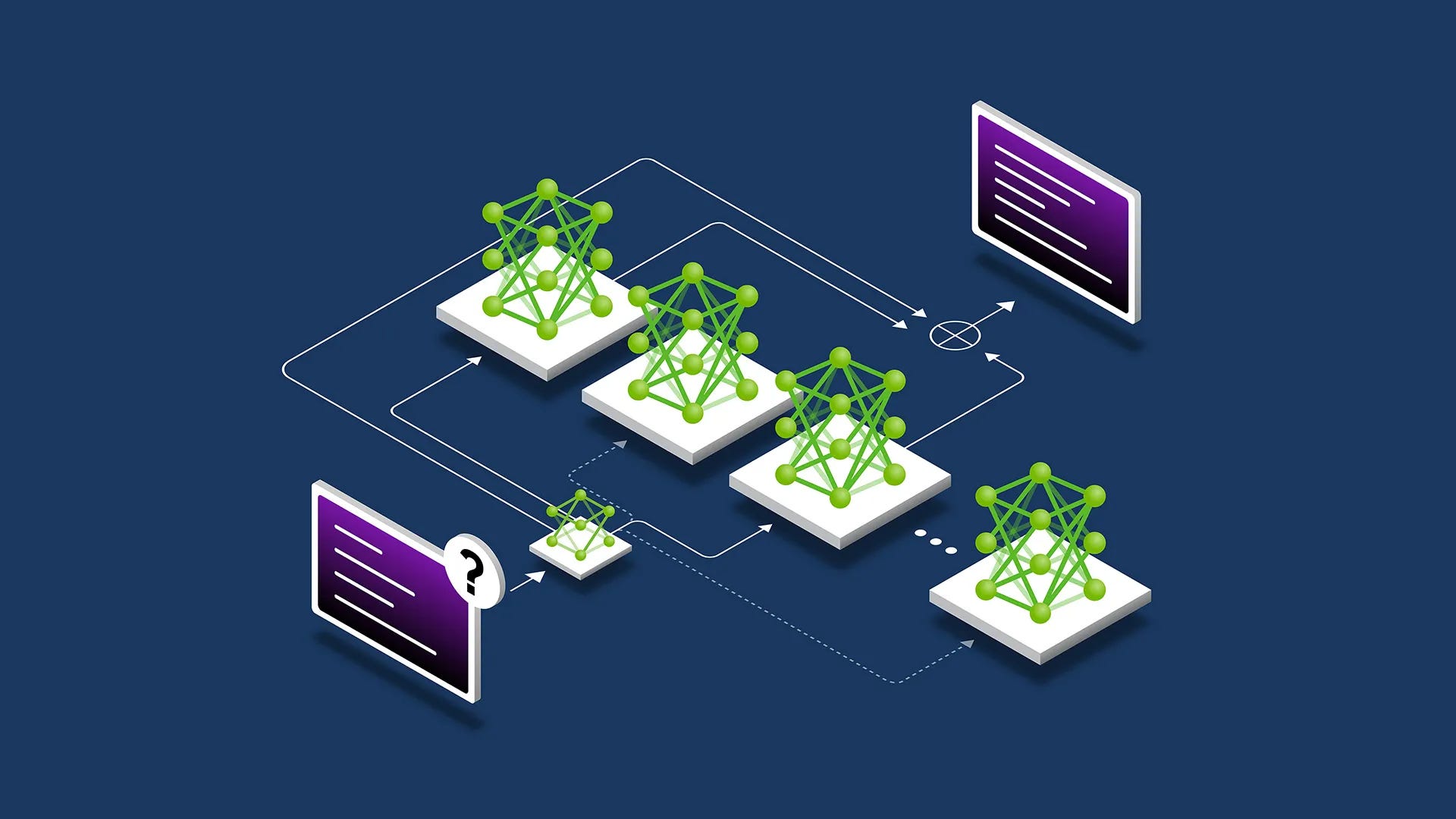
Mixture of Experts (MoE) architecture offers a more sophisticated approach, where different, separated “experts” are defined within the confines of a given model (only a small subset of these experts is activated for any given input). In practice, this approach allows the system to draw on specialist components when needed while keeping the rest of the model inactive, reducing the compute required and lowering the model’s energy cost.
All of these approaches are more cost-effective and sustainable options for inference compared to running the original model in full.
Divide and conquer
However, the greatest strength lies in specialisation. Initial homogenous systems are rapidly becoming multi-layered systems that optimise based on use case.
DeepSeek V3.1’s hybrid thinking mode toggles between reasoning and lightweight inference. Its “thinking” process is faster, choosing when and how to deploy its full capability based on the prompt. This increases the marginal efficiency of inference by only using the model’s full capability when truly necessary.
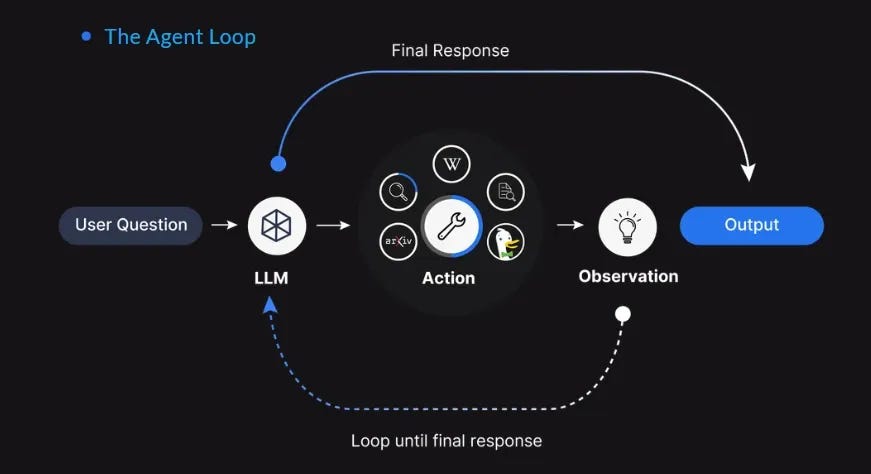
Models are also becoming more adept at calling tools. By offloading specialised subtasks to specific external tools (e.g. search engines or calculators), the model no longer has to solve every part of a task and can rely on the tool’s specialised functionality to perform more efficiently than a frontier model attempting to do the same job.
This tool-calling behaviour mirrors the broader API-based model emerging across the industry, where frontier models act as orchestrators: identifying tasks, selecting appropriate external APIs, and delegating work to specialised systems rather than solving everything internally.
For example, if you ask GPT5.1 to perform a simple calculation, it will not fire up the whole frontier model in a data centre in Montana to perform the calculation and send it back to you. Instead, it will summon a calculator tool to perform the calculation and present you the answer integrated within the same interface that translates a text or debugs your code, each of which would use a different model. GPT5 even drew controversy for doing this routing automatically, rather than allowing users to pick which model they wanted to interact with.
When the system is model agnostic, pruned or quantised models can then fit in, adapting the underlying model to each user query.
SLMs
The main driver of effective specialisation and potential future of the language model system is the Small Language Model (SLM). SLMs rely on the same underlying technology and mathematics, just more compact. They tend to feature a few billion parameters as opposed to frontier LLMs featuring hundreds of billions or trillions of parameters.
SLMs’ scale means they are faster and cheaper to deploy. A ~7B model is typically 10-30x cheaper to run and responds faster. You can fine-tune it overnight and even run it on a single GPU or device.
Some months ago, researchers from NVIDIA detailed a vision that suggested that the future of agentic systems will rely on the orchestration of multiple SLMs. They argue that:
While LLMs offer impressive generality and conversational fluency, the majority of agentic subtasks in deployed agentic systems are repetitive, scoped, and non-conversational—calling for models that are efficient, predictable, and inexpensive. Insisting on LLMs for all…tasks reflects a misallocation of computational resources—one that is economically inefficient and environmentally unsustainable at scale.
Indeed, over their lifetime SLMs can use just 30-40% of computational power compared to frontier models. Considering that AI systems have already used ~415 TWh in 2024 (~1.5% of global electricity) and grew rapidly this year, these savings are material.
SLMs can also be more secure and trustworthy because their limited capability becomes an asset. Smaller models are easier to monitor, test, audit, and control, and they carry lower systemic risk because their outputs are less complex and their actions more constrained. Although SLMs can still hallucinate, the scope and impact of those errors tend to be smaller, and the reduced volume of training data can simplify regulatory compliance. When failures do occur, their limited capability helps contain the potential fallout.
Living on the edge
The small scale of SLMs also enables greater flexibility for deployment. With lower compute requirements, these models can be hosted on individual computing devices rather than in enormous data centres — known as edge computing.
Assuming the device has the capability to (primarily) run SLMs, then the overall operation becomes more efficient. With a lower inference cost, the lack of transmission to and from a centralised data centre reduces overall energy demand and latency.
Of course, this efficiency assumes devices are already in use. The environmental cost of manufacturing millions of edge devices capable of running AI models must be weighed against the operational savings from distributed computing. Today, anywhere between 2-4bn edge devices (mostly comprised of newer laptops, PCs, and smartphones) could probably run a 7bn parameter model.
SLMs operating on edge devices also broaden use cases and access to the technology. Where connectivity is critical, such as in remote areas, SLMs run without needing large packages to be sent across large distances. Where latency is intolerable, such as in real-time translation, an on-device SLM designed for that task can provide a better experience than even the best frontier model. Where both are crucial, such as in autonomous vehicles, SLMs are clearly the best option.
Necessary but not sufficient
SLMs are clearly an important player in the development of more efficient and sustainable AI systems. The initial era of impressive scale has paved the way for a more specialised approach and incredible sophistication is required to make it work.
Execution is important here. SLMs are necessarily limited, and there is likely to be a sweet spot that is highly task-dependent. Some workloads will operate effectively on a 5 billion parameter model, others will require more or can get away with less.
The question is not are SLMs better than LLMs, but rather how to find the minimum viable scale for any given task. In practice, SLMs are best used for known, repeated tasks where they can be tested, starting small and monitoring for errors, incrementing size until the error rate falls below an acceptable standard. These models can then be called on by an orchestrating agent that picks the right model for each specific request, rather than defaulting to the bigger model every time. In practice, this can shift 40-70% of calls to small models with no quality loss. SLMs still struggle with long context, novel reasoning, or messy conversation. Deployers of these systems will still need to have a large model on hand, and evaluate performance regularly.
Greater architectural sophistication will continue to deliver efficiency gains, even as the economic pressures of compute intensify. Already we have seen the cost per token plummet 91% since 2023. The landscape is shifting quickly and the reduction in energy demand per token, matched with greater capability, may simply drive further usage.
The sharp fall in cost per token shows how quickly the landscape can shift, but it is uncertain whether this will rein in resource use or drive a surge in new applications. It is also unclear whether language models will stay at the core of AI systems or whether emerging model types will redefine the paradigm entirely. What happens next is impossible to predict with confidence, but the pace of progress suggests that change is unlikely to slow, especially as AI usage skyrockets.